FAULT DETECTION USING PRUNED NEURAL NETWORKS
Authors: Sunil Rao, Cihan Tepedelenlioglu, Andreas Spanias
Faults in utility-scale solar arrays [1]–[4] often lead to increased maintenance costs and reduced efficiency. Since photovoltaic (PV) arrays (Figure1.(a)) are generally installed in remote locations, maintenance and annual repairs due to faults incur large costs and delays. To automatically detect faults, PV arrays can be equipped with smart electronics that provide data for analytics. Smart monitoring devices (SMDs) [5] (Figure1.(b)) that have remote monitoring and control capability have been proposed [6] to provide data from each panel and enable detection and localization of faults and shading. The presence of such SMDs renders the solar array system as a cyber-physical system [7] that can be monitored and controlled in real-time with algorithms and software. Figure 1 shows a cyber-physical 18 kW PV testbed described in [8].
Even with the presence of SMDs, fault detection and classification is challenging and requires statistical analysis of PV data. The ability to classify faults accurately and automatically with various PV array connection topologies is still an open problem [9].

FIGURE 1. Smart solar array testbed monitoring system with SMDs at the ASU research park. (a) Solar array at the ASU research park consisting of 104 panels. (b) SMD which is fitted on to each individual panel. (c) SMD radio and relay switches which allow for real time switching and remote monitoring and control.
Our vision for research monitoring and optimizing a large-scale PV array is summarized in Figure 2. As shown in Figure 2, the array can be used to collect data in real time. Data collected from the array can be used for fault detection and classification studies. Switches with remote access also allow for dynamic topology reconfiguration. In this report, we use an autoencoder machine learning framework [11] to perform fault detection. An autoencoder is used to learn efficient representations (also called encodings) of the data through unsupervised dimensionality reduction. A decoder can then reconstruct the original input from the learned encoding. This unsupervised machine learning approach can be used to identify faults. We then implement fully connected NNs and dropout NNs [15] trained specifically for fault classification in PV arrays. In our results section, we discuss performance based on accuracy and computational complexity in terms of weighted accuracy for various architectures. To reduce computation and redundancy and to customize the NN, we also perform network pruning using the lottery ticket hypothesis optimization process [12] to design sparse NN architectures. We achieve a 2× reduction in the size of the NN. Along with custom hardware, which enables monitoring voltage, current, temperature, and irradiance at the module level [13], a custom NN with reduced parameters and high accuracy will be beneficial for the development of compact and specialized hardware for fault classification in PV arrays. Furthermore, we study the faults and their diagnosis from an operations and management perspective.
- RESEARCH CONTRIBUTIONS
We consider the problem of detection and classification of faults occurring in utility-scale PV array systems. First, we train an autoencoder for fault detection. More specifically, we use our custom features to train a 3-layer autoencoder to detect faults. We use the reconstruction error from the autoencoder to create an error histogram, which is used to identify faults. Next, we train a NN for PV fault classification using dropout and concrete dropout regularizers. We compare NNs against the standard machine learning (ML) classification algorithms described in reference [11], such as SVM, K-nearest neighbor (KNN), and random forest classifier (RFC). Additionally, we associate the performance of the classification algorithms to the hardness of data separation in PV arrays. We perform dimensionality reduction using the state-of-the-art Distributed Stochastic Neighbor Embedding (t-SNE) algorithm [14] and visualize clusters of faults which are inseparable. Our results show that the 2× pruned networks perform better than standard ML classifiers and concrete dropout has the best performance among all methods examined.
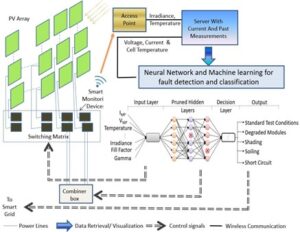 FIGURE 2. Smart solar array monitoring system with fault detection and classification systems. The autoencoder is used for fault detection while the pruned neural network is used for fault classification.
FIGURE 2. Smart solar array monitoring system with fault detection and classification systems. The autoencoder is used for fault detection while the pruned neural network is used for fault classification.
II. SOLAR ARRAY EXPERIMENTS AND RESULTS
We considered a set of 9-dimensional unique custom input features for the neural networks. These nine input features are known to provide high accuracy for fault classification on simulated data [10]. The dataset contains a total of 22000 samples. We feed the 22000 × 9 feature matrix to the NN. We use a 3-layer neural network with 50 neurons in each layer, as in [4], with tanh as our activation function for each layer.
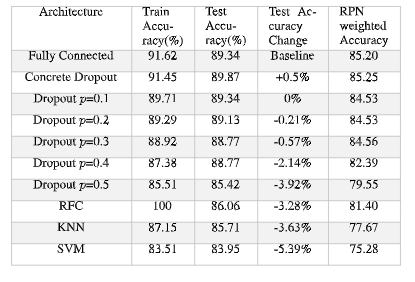
TABLE 1. Comparison of various classifiers used for fault classification in PV arrays. We note that the concrete dropout architecture performs best in terms of accuracy due to an optimized hyperparameter search within the architecture.
This architecture was fixed for all the NN simulations, to avoid any bias which may occur during training and testing. We consider multiple uniform dropout architectures with dropout probabilities p ∈ (0.1,0.2,0.3,0.4,0.5).All the networks were trained for 100 epochs to minimize categorical cross entropy loss using an Adam gradient descent optimizer.
Along with dropout neural networks for comparison, we performed fault classification using traditional machine learning classifiers, as reported in Table 1.In addition, Table 1 shows accuracy and run time for various algorithms. We also compare against results with fully connected neural networks (baseline) [4], [10]. We ran a Monte Carlo simulation on all the architectures mentioned to obtain estimates for training and testing. The training (70%) and testing (30%) dataset were sampled randomly in each run of the Monte Carlo simulation. We observe that dropout architectures perform quite well in terms of accuracy and run time. In fact, concrete dropout provided the best results. Among all the dropout architectures, we see an improvement of 0.5% when using a concrete dropout architecture in comparison to the fully connected neural network.
We also compared NNs performance with standard machine learning algorithms such as RFC, SVM and KNNs, and the results are reported in Table 1. For the ML algorithms, we performed a grid search over a range of parameters and chose the best configuration, by 3-fold cross validation on training data. Grid search is used to determine the optimal hyperparameters of a model which results in the most ‘accurate’ predictions. For the RFC classifier, we considered maximum depth in {10,25,50,100} and number of estimators in {5,10,25,50} and found that the best parameters were max depth of 25 and 50 estimators, with the best accuracy of 87.35 on the validation set. For the KNN classifier, we considered the number of Neighbors in {5,10,25,50,100,200} with Euclidean distance measure and found that the hyperparameter associated with the best accuracy of 86.18 on the validation set was obtained with the number of neighbors being 25. For the SVM classifier, we considered soft margin parameter C in {1,10,100,1000} and kernel in {linear, radial basis function} and found that the best parameters were C of 100 and linear kernel, with the best accuracy of 84.23 on the validation set. We observe that techniques such as the RFC overfits the training data, while other classifiers such as the SVM and the KNN perform poorly compared to NNs.
In order to evaluate the model’s ability to classify the data points belonging to the group with higher risk factors, we compared performance of different models based on RPN weighted accuracy. The RPN weighted accuracy (RWA) is calculated by summing the products of normalized RPN scores with its class-wise accuracy, written as,
![]()
where, A1,A2,A3,A4,A5 are class-wise accuracy’s of standard test conditions, soiling, shading, degraded and short circuit faults, respectively. We observed that the concrete dropout has superior RWA performance over the other models, as well as the best overall test accuracy, thus it is consistent in correctly classifying all faults classes considered in PV array monitoring systems.

FIGURE 3. PV fault classification and confusion matrix obtained with Concrete Dropout.
For the network pruning experiments, we consider NNs with 3 hidden layers each with N = {50,100,200,500,1000} neurons. All NNs were trained for 150 epochs and at every pruning iteration 10% of the remaining weights were pruned. We used the ReLU activation function for all the neurons and the network was trained to minimize categorical cross entropy loss using a mini-batch gradient descent optimizer. We find that smaller networks achieve greater compression of about 62% for a drop in accuracy by 4%, as shown in Figure 4. The performance of larger networks degrades by up to 40% after pruning the network. We also observe that our pruned neural network algorithms have an accuracy within 2% of the fully connected neural network algorithm for a 40% reduction of the weights of the neural network. Interestingly, we also find that the overlapping points correspond to the incorrectly classified points in the confusion matrix, shown in Figure 3, which includes approximately 10% of the data.
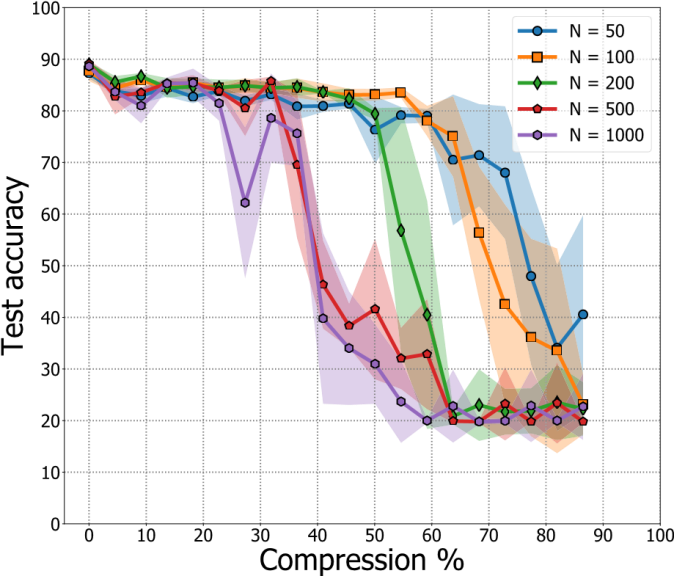
FIGURE 4. PV fault test accuracy (mean and standard deviation) of pruned NNs for different pruning %. All NNs have 3 hidden layers, each with N neurons. From our results, we observe that when N= 100, a 2x reduction in the number of parameters does not significantly affect the accuracy.
III. REMARKS
In this report, we propose and characterize efficient neural network architectures for fault detection and classification in utility scale solar arrays. We study the faults and their diagnosis from an operations and management perspective to offer an experimental perspective.
We first use an autoencoder to detect faults. We detect faults based on the histogram reconstruction error. We then customize and optimize neural network architectures with concrete dropout mechanisms for fault classification in PV arrays. We examine the fault classification accuracy for each class. We characterize algorithms in terms of performance and complexity and more specifically we compare the proposed concrete dropout method with fixed dropout and fully connected NNs. We also compare our work against standard machine learning algorithms. We observe that concrete dropout outperforms other methods with a classification accuracy of 89.87% as shown in Table 1 and has the fastest run time on the test dataset. In order to reduce complexity, we also explore the use of pruned neural networks. Using Monte Carlo simulations, we demonstrate that the test accuracy of a network pruned by 50% (a significant reduction of weights) reduces only by 3%. The pruned network, represented by half the number of parameters, will be useful for the development of customized and efficient fault detection hardware and software for PV arrays. In addition, we evaluated faults using their RPN and their corresponding safety category. We also perform a weighted class average and examine the class wise accuracy of these faults. Since the RPN associated with these faults is high and poses a greater safety threat, the detection and classification of such faults is critical.
REFERENCES
[1] M. Köntges, S. Kurtz, C. Packard, U. Jahn, K. A. Berger, K. Kato,T. Friesen, H. Liu, M. Van Iseghem, J. Wohlgemuth et al., “Review offailures of photovoltaic modules,” IEA International Energy Agency, 2014.
[2] M. Köntges, G. Oreski, U. Jahn, M. Herz, P. Hacke, K.-A. Karl-Anders Weiss, G. Razongles, P. Marco, P. David, T. Tanahashi et al., “Assessment of photovoltaic module failures in the field,” IEA International Energy Agency, 2017.
[3] J. M. Kuitche, G. TamizhMani, and R. Pan, “Failure modes effects and criticality analysis (fmeca) approach to the crystalline silicon photovoltaicmodule reliability assessment,” in Reliability of Photovoltaic Cells, Mod-ules, Components, and Systems IV, vol. 8112.International Society forOptics and Photonics, 2011.
[4] A. Mellit, G. M. Tina, and S. A. Kalogirou, “Fault detection and diagnosis methods for photovoltaic systems: A review,” Renewable and Sustainable Energy Reviews, vol. 91, pp. 1–17, August 2018.
[5] T. Takehara and S. Takada, “Photovoltaic panel monitoring apparatus,”U.S. Patent 8,410,950, April 2 2013.
[6] H. Braun, S. T. Buddha, V. Krishnan, A. Spanias, C. Tepedelenlioglu,M. Banavar, S. Takada, T. Takehara, and T. Yeider, Signal processing forsolar array monitoring, fault detection, and optimization. Morgan &Claypool Publishers, vol. 7, no. 1, pp. 1–95, September 2012.
[7] A. S. Spanias, “Solar energy management as an Internet of Things (IoT)application,” in 8th International Conference on Information, Intelligence,Systems & Applications (IISA). IEEE, Larnaca, Cyprus, 2017.
[8] S. Rao, D. Ramirez, H. Braun, J. Lee, C. Tepedelenlioglu, E. Kyriakides,D. Srinivasan, J. Frye, S. Koizumi, Y. Morimoto et al., “An 18 kWsolar array research facility for fault detection experiments,” in 201618th Mediterranean Electrotechnical Conference (MELECON).IEEE,Limassol, Cyprus, 2016.
[9] H. Braun, S. Buddha, V. Krishnan, C. Tepedelenlioglu, A. Spanias, M. Ba-navar, and D. Srinivasan, “Topology reconfiguration for optimization of photovoltaic array output,” SEGAN, vol. 6, pp. 58–69, June 2016.
[10] S. Rao, A. Spanias, and C. Tepedelenlioglu, “Solar array fault detection us-ing neural networks,” in 2019 IEEE International Conference on IndustrialCyber Physical Systems (ICPS), Taiwan, May, 2019.
[11] I. Goodfellow, Y. Bengio, and A. Courville, Deep learning, MIT Press,November 2016.
[12] J. Frankle and M. Carbin, “The lottery ticket hypothesis: Finding sparse, trainable neural networks,” International Conference on Learning Representations, May 2019.
[13] G. Muniraju, S. Rao, S. Katoch, A. Spanias, C. Tepedelenlioglu, P. Turaga,M. K. Banavar, and D. Srinivasan, “A cyber-physical photovoltaic array monitoring and control system,” IJMSTR, vol. 5, no. 3, pp. 33–56, May2017.
[14] L. v. d. Maaten and G. Hinton, “Visualizing data using t-sne,” Journal ofMachine Learning Research, vol. 9, pp. 2579–2605, Nov 2008.
[15] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdi-nov, “Dropout: a simple way to prevent neural networks from overfitting,” Journal of Machine Learning Research, vol. 15, no. 1, pp. 1929–1958,January 2014.
[16] Sunil Rao, Gowtham Muniraju, Cihan Tepedelenlioglu, Devarajan Srinivasan, Govindasamy Tamizhmani, and Andreas Spanias. “Dropout and Pruned Neural Networks for Fault Classification in Photovoltaic Arrays.” IEEE Access, Vol 9, August 2021.
Solar Array Reconfiguration for Optimizing Power Output using Regularized Neural Networks
Authors: Vivek Narayanaswamy, Raja Ayyanar, Cihan Tepedelenlioglu, Devarajan Srinivasan and Andreas Spanias
Introduction
Reconfiguring photovoltaic (PV) array connections to realize alternate topologies such as series-parallel, bridge-link, honeycomb or total cross tied is a commonly adopted strategy to mitigate the impediments in power production caused by partial shading. Conventional approaches rely on by-passing shaded modules in an array by connecting auxiliary unshaded panels through complex control mechanisms or utilizing a simulator driven heuristic approach to predict the best topology. However, these solutions are not scalable and incur significant installation costs and computational overhead motivating the need to develop `smart’ and automated methods for topology reconfiguration. To this end, in this paper, we propose a regularized neural network-based algorithm that leverages panel level sensor data to reconfigure the array to the topology that maximizes the power output under arbitrary shading conditions. Based on extensive simulations we observe power improvement through reconfiguration under modeled wiring losses. The proposed algorithm can be easily deployed in any PV array with reconfiguration capabilities and is scalable.
Short Summary of the Algorithm
The following shows the standard configurations considered for topology optimization (Fig. 1)

Fig. 1 The four different topologies used in the CPS topology reconfiguration study.
We first create synthetic data for the four, 5×5 topologies using MATLAB. We create a feature matrix consisting of the panel level irradiances. The target label is the topology that produces maximum power given an irradiance instance from that feature matrix. In this work, we design a six-layered multi-layer perceptron (MLP) model with dropout and batch norm to perform topology reconfiguration. Dropout randomly sets the weights and gradients of p% of the neurons in a layer to zero during every training iteration thereby regularizing the network and preventing overfitting. Batch norm tackles the internal covariate shifts between every layer and leads to faster convergence. The neural network is trained with the irradiance instances along with the label of the configuration which provides the maximum power among the possible configurations considered for that irradiance profile.
Based upon the real-time irradiance input from every panel, the configuration optimizes to produce the maximum power.

Fig. 2 Neural Network used for Topology Selection
Brief Remarks on Results
We find the average percentage improvement in power when switching from SP to the other topologies to be approximately 11%. More details on the algorithm, results and conclusions in the IEEE PES 2021 submission.
References:
[1] Braun, H., Buddha, S. T., Krishnan, V., Tepedelenlioglu, C., Spanias, A., Banavar, M., & Srinivasan, D. (2016). Topology reconfiguration for optimization of photovoltaic array output. Sustainable Energy, Grids and Networks, 6, 58-69.
[2] Sunil Rao, David Ramirez, Henry Braun, Jongmin Lee, Cihan Tepedelenlioglu, Elias Kyriakides, Devarajan Srinivasan, Jeffrey Frye, Shinji Koizumi, Yoshitaka Morimoto and Andreas Spanias, “An 18 kW Solar Array Research Facility for Fault Detection Experiments”, MELECON, Cyprus, April 2016.
[3] El-Dein, MZ Shams, Mehrdad Kazerani, and M. M. A. Salama. “Optimal photovoltaic array reconfiguration to reduce partial shading losses.” IEEE Trans. Sustain. Energy 4.1 (2013): 145-153.
[4] Patel, Hiren, and Vivek Agarwal. “MATLAB-based modeling to study the effects of partial shading on PV array characteristics.” (2008).
[5] Tria, Lew Andrew R., Miguel T. Escoto, and Carl Michael F. Odulio. “Photovoltaic array reconfiguration for maximum power transfer.” TENCON 2009-2009 IEEE Region 10 Conference. IEEE, 2009.
[6] Vivek Narayanaswamy, Raja Ayyanar, Cihan Tepedelenlioglu, Devarajan Srinivasan and Andreas Spanias, Solar Array Reconfiguration for Optimizing Power Output using Regularized Neural Networks,” Submitted IEEE PES, Nov. 2021
METEOROLOGICAL PARAMETERS BASED IRRADIANCE FORECASTING
Authors: Sameeksha Katoch, Cihan Tepedelenlioglu, Devarajan Srinivasan, Pavan Turaga, Andreas Spanias
Irradiance prediction and forecasting has been one of the key aspects in efficiently designing the photovoltaic (PV) systems. Since clouds are one of the major causes of intermittency and uncertainty in PV power generation, in this work we utilize cloud type information along with other weather features to solve the problem of irradiance prediction which directly affects the power output for smart grids. The overview of the proposed pipeline is shown in Figure 1.
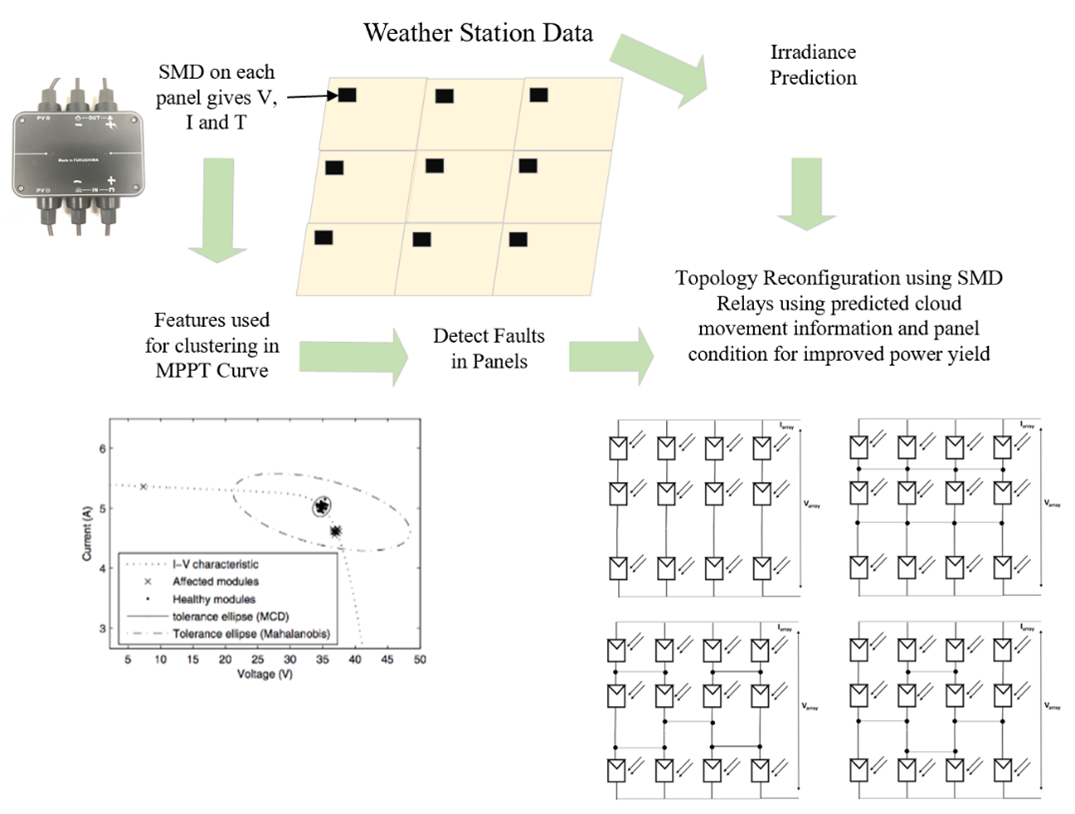
Figure 1. Illustration of Photovoltaic pipeline wherein we show how weather data-based irradiance prediction is used for topology reconfiguration and hence optimizing the power output.
To this end, for irradiance prediction we propose to utilize Temporal Convolutional Network [1] on a challenging dataset from National Solar Radiation Database (NSRDB). The 1-year long data from NSRDB database has been collected at a 30-min time resolution [2]. The data provides several markers for identification such as, ‘City’, ‘State’, ‘Country’, ‘Latitude’, ‘Longitude’, ‘Time Zone’, ‘Elevation’ and ‘Local Time Zone’. The specified data includes 9 major features which are utilized to predict the Global Horizontal irradiance (GHI) value. The features include ‘Dew Point’ (temperature below which water droplets begin to condense), ‘Solar Zenith Angle’ (angle between sun’s rays and the vertical), ‘Cloud Type’, ‘Surface Albedo’ (fraction of the sunlight reflected by the surface of the Earth), ‘Wind Speed’, ‘Precipitable water’ (total atmospheric water vapor contained in a vertical column of unit cross-sectional area extending between any two specified levels), ‘Relative Humidity’ (a present state of absolute humidity relative to a maximum humidity given the same temperature), ‘Temperature’ and ‘Pressure’. The dataset identifies cloud type into 13 categories including Clear, Probably Clear, Fog, Water, Super-Cooled Water, Mixed, Opaque Ice, Cirrus, Overlapping, Overshooting, Unknown, Dust, Smoke types. Corresponding to the input features, the dataset is composed of corresponding GHI values which are used as labels/target for the purpose of this research. Using this dataset, we perform an empirical analysis regarding which features show a strong correlation with the irradiance values. Using course irradiance prediction, we determine that features such as solar zenith angle, cloud types, temperature and surface albedo are strongly correlated with the irradiance and hence monitoring those features can aid in pre-planning the storage and efficient utilization of the power output from a PV array. Furthermore, we perform short term irradiance forecasting comparison with existing prediction techniques such as Natural Gradient Boosting and Long Short Term Memory (LSTM) to analyze which methods perform significantly well compared to the counterparts. We were able to show that using TCN, we can achieve Mean Square Error as low as 0.16 on the test data i.e. we were able to get upto ~8% improvement compared to standard LSTM.
In the next steps, for this work we aim to implement the forecasting techniques on real dataset to capture the variability of the seasons better. Furthermore, we do short term irradiance forecasting i.e. next 2 time steps. In future work, we would like to explore the methods which would work for longer duration.
References
- Bai, S., Kolter, J. Z., & Koltun, V. “An empirical evaluation of generic convolutional and recurrent networks for sequence modeling.”, arXiv preprint arXiv:1803.01271, 2018
- Sengupta, M., Xie, Y., Lopez, A., Habte, A., Maclaurin, G., & Shelby, J. “The national solar radiation data base (NSRDB).”, Renewable and Sustainable Energy Reviews, 89, 51-60, 2018.
RESULTS OF USING GRAPH SIGNAL PROCESSING FOR FAULT DETECTION
Authors: Jie Fan, Cihan Tepedelenlioglu, Andreas Spanias
In our previous year work, we proposed a graph-based semi-supervised classifier for fault detection in photovoltaic (PV) arrays. The graph-based classifiers require less training samples compared to the standard supervised machine learning algorithms.
In our latest research, a new graph filter design method with the split-and-merge scheme is developed for fault detection in PV arrays. As shown in Fig 1, our new algorithm adopts a learning algorithm to split original graph into multiple subgraphs and design subgraph filters parallelly. Then, after merging all the filters together, we can obtain the final graph filter as the classifier for the fault detection. Through the graph filter with the split-and-merge scheme, we can reduce the redundant information in the original graph, which can save the computational cost of the graph generation and graph design. In our simulation experiments, the new algorithm can achieve similar accuracy to the conventional graph-based classifier while reducing 70% of the CPU time. This algorithm will be part of a journal paper which is in preparation.

Fig 1. The pipeline of graph filter design with split-and-merge scheme.
Papers and Patents published in 2021
[1] S. Katoch, P. Turaga, A. Spanias, C. Tepedelenlioglu, P. Turaga, “Systems and methods for skyline prediction for cyber-physical photovoltaic array control”, US Patent 11,132,551, Issued Sept. 2021
[2] Kristen Jaskie, Joshua Martin, Andreas Spanias, “Systems and Methods for Photovoltaic Fault Detection using a Feedback-Enhanced Positive Unlabeled Learning Method, USA Provisional 63/109,18
[3] S. Rao, G. Muniraju, C. Tepedelenlioglu, D. Srinivasan, G. Tamizhmani and A. Spanias, “Dropout and Pruned Neural Networks for Fault Classification in Photovoltaic Arrays”, IEEE Access, 2021
[4] K. Jaskie, J. Martin, and A. Spanias, “PV Fault Detection using Positive Unlabeled Learning”, Applied Sciences, vol. 11, Jun. 2021
[5] Glen Uehara, Sunil Rao, Mathew Dobson, Cihan Tepedelenlioglu and Andreas Spanias, “Quantum Neural Network Parameter Estimation for Photovoltaic Fault,” Proc. IEEE IISA 2021, July 2021
[6] J. Martin, K. Jaskie, Y. Tofis, A. Spanias, ”PV Array Soiling Detection using Machine Learning Fault Detection”, Proc. IEEE IISA 2021, July 2021